Data Validation Without Objects
Yehonathan Sharvit
15 Sep 2021
•
7 min read

According to Data-Oriented Programming, we should represent data with generic and immutable data structures, like immutable hash maps and immutable vectors. At first sight, it might seem that it means to live in the wild and not validate that data is conformed to an expected schema.
In fact, it is possible -- and advised -- to maintain a data schema in Data-Oriented Programming. The major insight of Data-Oriented Programming regarding data validation is that data schema should be separated from data representation.
We should separate data schema from data representation.
This article is made of 4 parts:
- How to express a data schema using JSON schema
- How to validate data against a JSON schema
- The benefits of separating between data schema and data representation
- The costs of separating between data schema and data representation
JSON schema
Think about handling a request in a library management system for the addition of an author to the system. To keep things simple, imagine that such a request contains only basic information about the author:
- Their first name
- Their last name
- Optionally, the number of books they have written
In Data-Oriented Programming, we represent the request data in our program as a string map that is expected to have three fields:
firstName- a stringlastName- a stringbooks- a number (optional)
Using JSON schema, we represent the data schema of the request with the following map:
var addAuthorRequestSchema = {
"type": "object",
"required": ["firstName", "lastName"],
"properties": {
"firstName": {"type": "string"},
"lastName": {"type": "string"},
"books": {"type": "integer"}
}
};
A couple of remarks regarding the syntax of this JSON schema:
- Data is expected to be a map (in JSON, a map is called an object)
- Only
firstNameandlastNamefields are required firstNamemust be a stringlastNamemust be a stringbooksmust be an integer (when it is provided)
Data validation against a schema
In order to check whether a piece of data conforms to a data schema, we use a data validation library. For instance, using Ajv JSON schema validator, we validate a piece of data using the validate function.
As you might expect, when a piece of data is valid, validate returns true:
var validAuthorData = {
firstName: "Isaac",
lastName: "Asimov",
books: 500
};
ajv.validate(addAuthorRequestSchema, validAuthorData); // true
When a piece of data is invalid (e.g. using lastNam instead of lastName), validate returns false:
var invalidAuthorData = {
firstName: "Isaac",
lastNam: "Asimov",
books: "five hundred"
};
ajv.validate(addAuthorRequestSchema, invalidAuthorData); // false
When a piece of data is invalid, we can easily get details about data validation failures in a human readable format:
var invalidAuthorData = {
firstName: "Isaac",
lastNam: "Asimov",
books: "five hundred"
};
var ajv = new Ajv({allErrors: true});
ajv.validate(addAuthorRequestSchema, invalidAuthorData);
ajv.errorsText(ajv.errors);
// "data should have required property 'lastName', data.books should be number"
A couple of remarks regarding validation with Ajv:
- By default, Ajv stores only the first data validation error. We use
allErrors: trueto store all errors. - Data validation errors are stored internally as an array. In order to get a human readable string, we use
errorsTextfunction.
The benefits of separating between data schema and data representation
When we separate data schema from data representation in our programs, our programs benefit from:
- Freedom to choose what data should be validated
- Optional fields
- Advanced data validation conditions
- Automatic generation of data model visualization
Benefit# 1: Freedom to choose what data should be validated
When data schema is separated from data representation we are free to instantiate data without specifying its expected shape. Such a freedom is useful in various situations. For example:
- We want to experiment with code quickly
- Data has already been validated
Rapid prototyping
In classic Object-Oriented Programming and in some statically typed Functional Programming, each and every piece of data must have a predefined shape (either a class or a data type). During the exploration phase of coding, where we don't know yet what is the exact shape of our data, being forced to update the type definition each time we update our data model slows us down. In Data-Oriented Programming, we can develop at a fast pace during the exploration phase, by delaying the data schema definition to a later phase.
Code refactoring
One common refactoring pattern is the split phase refactoring where you basically split a single large function into multiple smaller functions, with a private scope. Those functions are called with data that has already been validated by the large function. In Data-Oriented Programming, we are free to not specify the shape of the arguments of the inner functions, relying on the data validation that has already occurred.
Suppose we want to display some information about an author, like their full name and whether they are considered as prolific or not.
First, we define the data schema for the author data:
var authorSchema = {
"type": "object",
"required": ["firstName", "lastName"],
"properties": {
"firstName": {"type": "string"},
"lastName": {"type": "string"},
"books": {"type": "integer"}
}
};
Then, we write a displayAuthorInfo function that first check whether data is valid and then displays the information about he author:
function displayAuthorInfo(authorData) {
if(!ajv.validate(authorSchema, authorData)) {
throw "displayAuthorInfo called with invalid data";
};
console.log("Author full name is: ", authorData.firstName + " " + authorData.lastName);
if(authorData.books == null) {
console.log("Author has not written any book");
} else {
if (authorData.books > 100) {
console.log("Author is prolific");
} else {
console.log("Author is not prolific");
}
}
}
Notice that the first thing we do inside the body of displayAuthorInfo is to validate that the argument passed to the function is valid.
Now, let's apply the split phase refactoring pattern to this simplistic example and split the body of displayAuthorInfo in two inner functions:
displayFullName: Display the author full namedisplayProlificity: Display whether the author is prolific or not
function displayFullName(authorData) {
console.log("Author full name is: ", authorData.firstName + " " + authorData.lastName);
}
function displayProlificity(authorData) {
if(authorData.books == null) {
console.log("Author has not written any book");
} else {
if (authorData.books > 100) {
console.log("Author is prolific");
} else {
console.log("Author is not prolific");
}
}
}
function displayAuthorInfo(authorData) {
if(!ajv.validate(authorSchema, authorData)) {
throw "displayAuthorInfo called with invalid data";
};
displayFullName(authorData);
displayProlificity(authorData);
}
Having the data schema separated from the data representation allows us not to specify a data schema for the arguments of the inner functions displayFullName and displayProlificity. It makes the refactoring process a bit smoother.
In some cases, the inner functions are more complicated and it makes sense to specify a data schema for their arguments. Data-Oriented Programming gives us the freedom to choose!
Benefit# 2: Optional fields
In Object-Oriented Programming, allowing a class member to be optional is not easy. For instance, in Java one needs a special construct like the Optional class introduced in Java 8.
In Data-Oriented Programming, it is natural to declare a field as optional in a map. In fact in JSON schema, by default every field is optional. In order to make a field non-optional, we have to include its name in the required array as for instance in the author schema in the following code snippet where only firstName and lastName are required while books is optional.
var authorSchema = {
"type": "object",
"required": ["firstName", "lastName"], // `books` is not included in `required`, as it is an optional field
"properties": {
"firstName": {"type": "string"},
"lastName": {"type": "string"},
"books": {"type": "integer"} // when present, `books` must be an integer
}
};
Let's illustrate how the validation function deals with optional fields: A map without a books field is considered to be valid:
var authorDataNoBooks = {
"firstName": "Yehonathan",
"lastName": "Sharvit"
};
validate(authorSchema, authorDataNoBooks) // true
However, a map with a books field where the value is not an interger is considered to be invalid:
var authorDataInvalidBooks = {
"firstName": "Albert",
"lastName": "Einstein",
"books": "Five"
};
validate(authorSchema, authorDataInvalidNoBooks) // false
Benefit# 3: Advanced data validation conditions
In Data-Oriented Programming, data validation occurs at run time. It allows us to define data validation conditions that go beyond the type of a field. For instance, we might want to make sure that a field is not only a string but a string with a maximal number of characters or a number comprised in a range of numbers.
For instance, here is a JSON schema that expects firstName and lastName to be strings of less than 100 characters and books to be a number between 0 and 10,000:
var authorComplexSchema = {
"type": "object",
"required": ["firstName", "lastName"],
"properties": {
"firstName": {
"type": "string",
"maxLength": 100
},
"lastName": {
"type": "string",
"maxLength": 100
},
"books": {
"type": "integer",
"minimum": 0,
"maximum": 10000
}
}
};
JSON schema supports many other advanced data validation conditions, like regular expression validation for string fields or number fields that should be a multiple of a given number.
Benefit# 4: Automatic generation of data model visualization
When the data schema is defined as data, we can leverage tools that generate data model visualization: with tools like JSON Schema Viewer and Malli we can generate a UML diagram out of a JSON schema. For instance, the following JSON schema defines the shape of a bookList field that is an array of books where each book is a map.
{
"type": "object",
"required": ["firstName", "lastName"],
"properties": {
"firstName": {"type": "string"},
"lastName": {"type": "string"},
"bookList": {
"type": "array",
"items": {
"type": "object",
"properties": {
"title": {"type": "string"},
"publicationYear": {"type": "integer"}
}
}
}
}
}
The tools we just mentioned can generate the following UML diagram from the JSON schema:
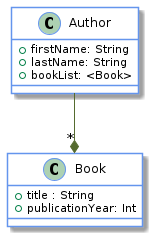
The costs of separating between data schema and data representation
There is no such thing as a free lunch. Separating between data schema and data representation comes at a cost:
- Loose connection between data and its schema
- Light performance hit
Cost# 1: Loose connection between data and its schema
By definition, when we separate between data schema and data representation, the connection between data and its schema is looser that when we represent data with classes. Moreover, the schema definition language (e.g. JSON schema) is not part of the programming language. It is up to the developer to decide where data validation is necessary and where it is superfluous.
As the idiom says, with great power comes great responsibility.
Cost# 2: Light performance hit
As we mentioned earlier, there exist implementations of JSON schema validation in most programming languages. When data validation occurs at run time it takes some time to run the data validation while in Object-Oriented programming, data validation occurs usually at compile time.
This drawback is mitigated by the fact that even in Object-Oriented programming some parts of the data validation occur at run time. For instance, the conversion of a request JSON payload into an object occurs at run time. Moreover, in Data-Oriented Programming, it is quite common to have some data validation parts enabled only during development and to disable them when the system runs in production.
As a consequence, the performance hit is not significant.
Wrapping up
In Data-Oriented Programming, data is represented with immutable generic data structures. When additional information about the shape of the data is required, we are free to define a data schema (e.g. in JSON Schema).
Keeping the data schema separate from the data representation gives freedom to the developer that is free to decide where data should be validated. Moreover, data validation occurs at run-time. As a consequence, we can express data validation conditions that go beyond the static data types (e.g. the string length).
However, with great power comes great responsibility and it's up to the developer to remember to validate data.
Yehonathan Sharvit
Full-Stack Web Consultant. Expert in Clojure, ClojureScript and Javascript.
See other articles by Yehonathan

WorksHub
Jobs
Locations
Articles
Ground Floor, Verse Building, 18 Brunswick Place, London, N1 6DZ
108 E 16th Street, New York, NY 10003
Subscribe to our newsletter
Join over 111,000 others and get access to exclusive content, job opportunities and more!