Complex Systems Approach to Software Development
Eugene Naumenko
21 Apr 2022
•
12 min read
The Landscape
Software development is a human activity of solving business problems by building complex software systems using technology. It is also a system, as in systems theory, consisting of many subsystems, and interacting with many other systems and the environment.
Let’s try to apply some scientific thinking to understand what it is about, and predict what to expect next. We will use ideas from evolutionary biology, complexity theory, chaos theory, systems theory, neurophysiology, anthropology, thermodynamics and some quantum physics.
Two of the most important parameters of software development seem to be human efforts and technological complexity, as formulated by Alan Kay:
[...] the most important aspects of a programming language are to have both (a) the most powerful semantic frameworks for expressing meaning, and (b) to be as learnable and readable and “gistable” as possible for human users.
– see Alan Kay's post.
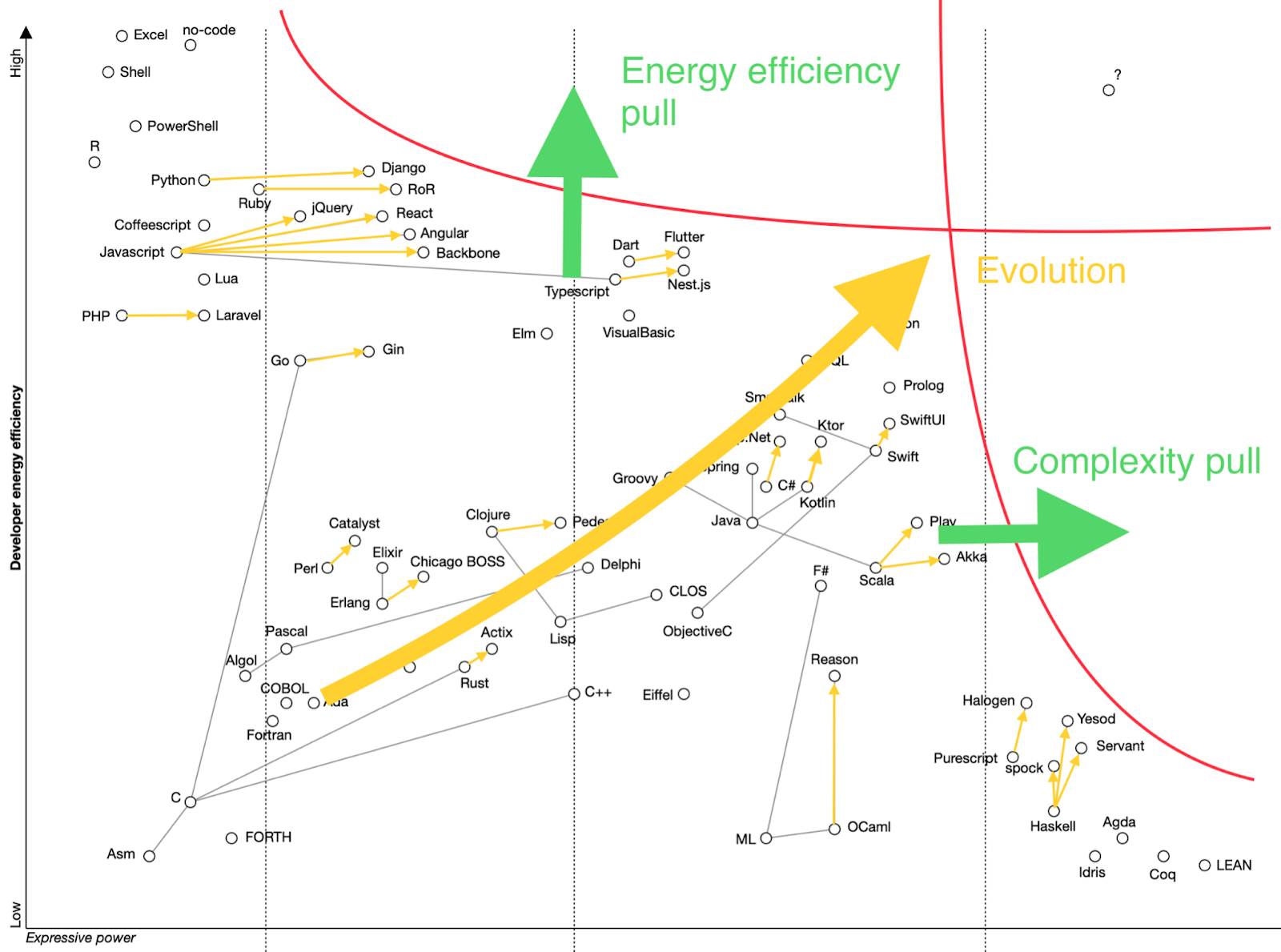
Human efforts can be measured in energy efficiency. The easier it is for a person to work with a tool and achieve results the more energy efficient the tool is, and vice versa. Also, energy efficiency is one of the key drivers of evolution, as we shall see later.
Technological complexity can be addressed with the expressive power of technology. The more complex solutions we have to build the higher expressive power the technology to build it must have. Complexity pulls the solutions towards using more powerful technology.
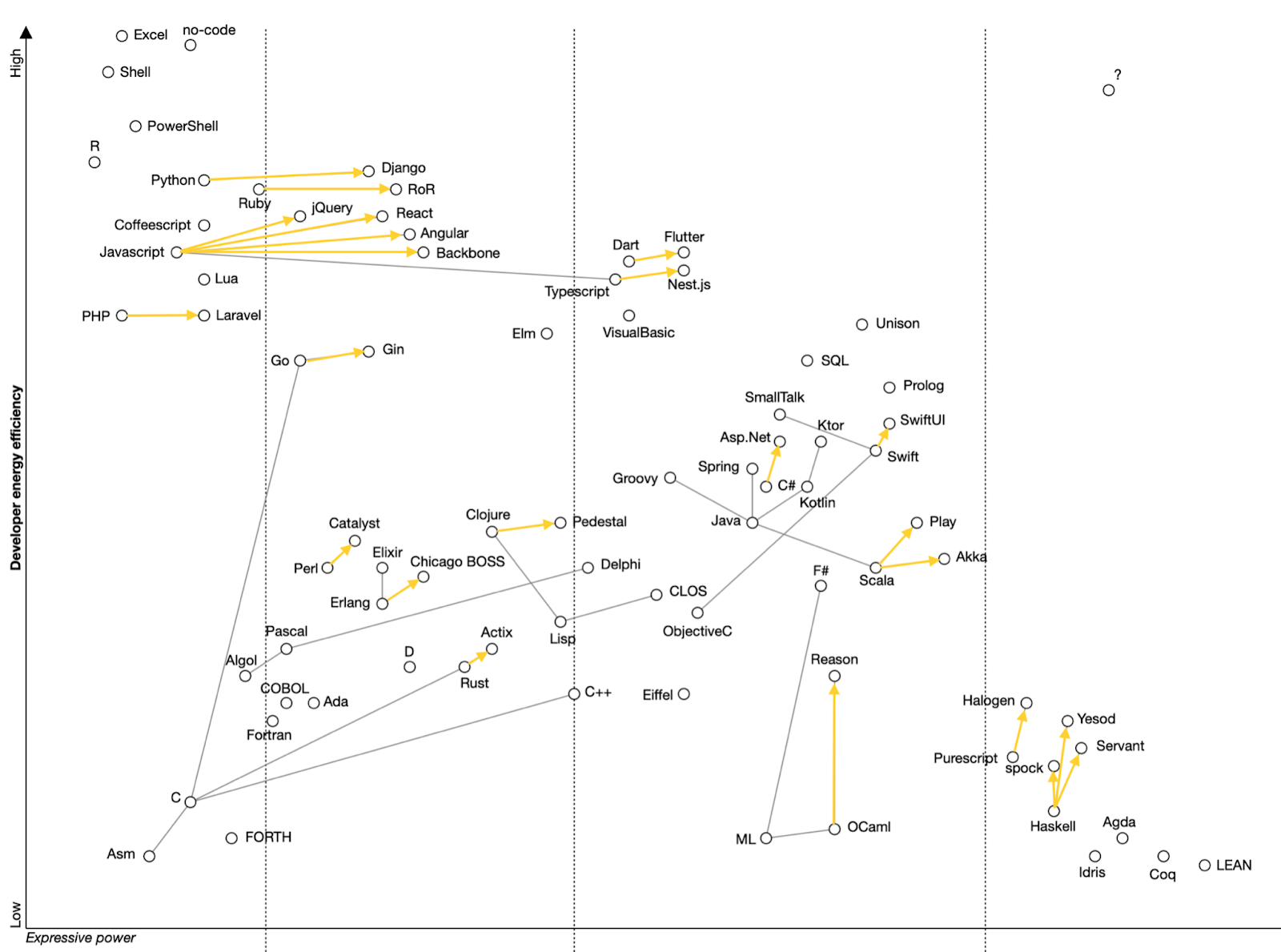
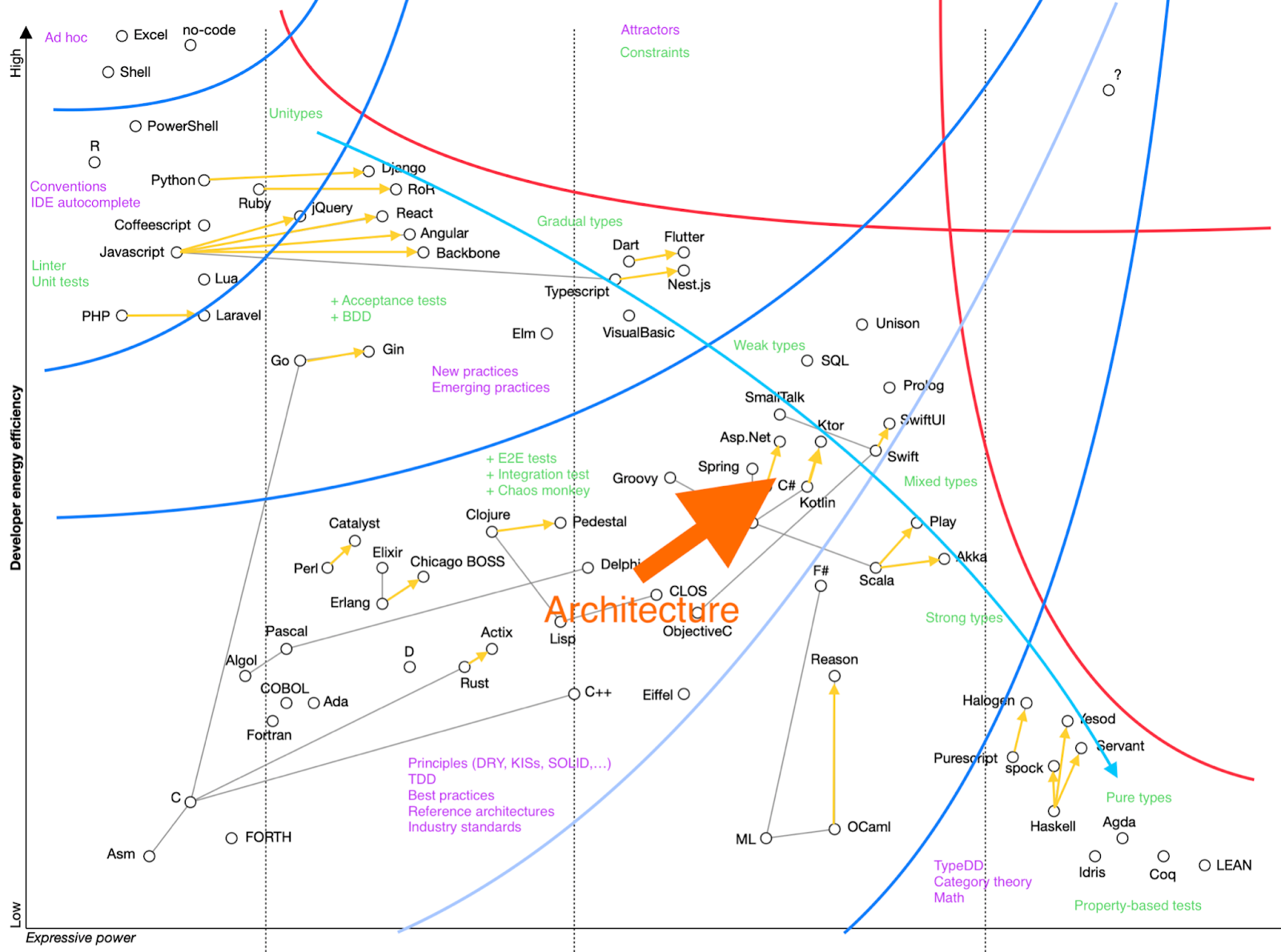
Let’s map the existing software industry technologies using these two parameters. Let’s make the vertical axis to be Developer energy efficiency with a given technology, from Low to High. The horizontal axis would be Expressive power of the technology, also from Low to High.
We shall also remember that there are many more parameters in the system which we ignore, or just can’t even know. This means that positions of elements on the chart aren’t precise or deterministic. Rather the positions are probabilities, with the depicted ones being the most probable places for elements. It is possible that elements can occasionally be placed anywhere else on the chart.
The basic technologies used in software development are programming languages and frameworks. Frameworks are an interesting case, because they evolve towards fixing languages to a direction of the real world needs. Lines between elements show some of the more interesting evolutionary connections between elements.
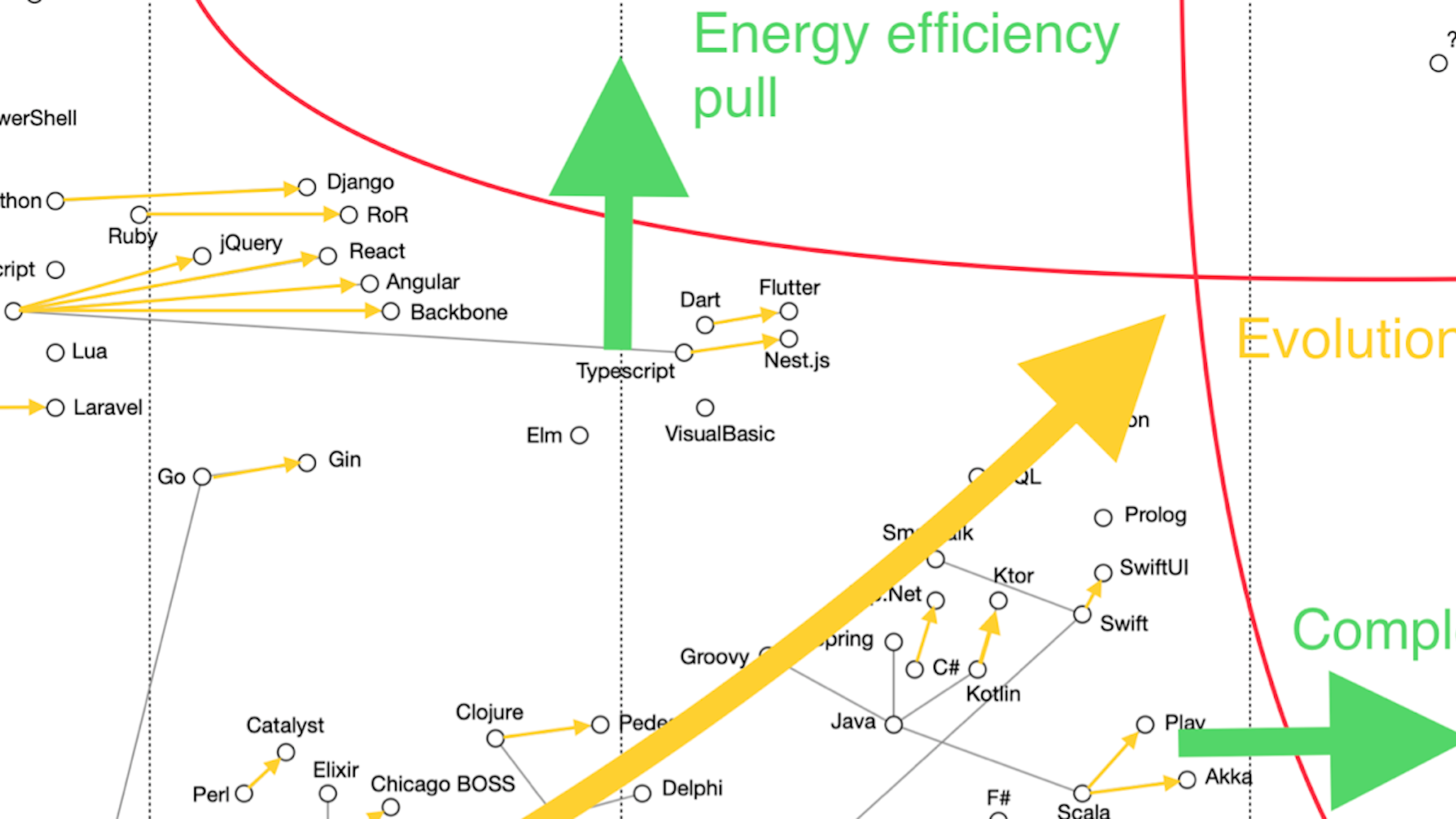
The Evolution
Here we can see the first interesting high-level pattern: lines of framework evolution are co-aligned within clusters of elements, and point towards the same area - the top right corner. We’ll get back there later.
Another interesting pattern is distinct clusters in the top left corner, bottom right corner and the stripe in the middle. Let’s make sense why it is so.
We can also see evolutionary forces in play as a third set of high level patterns:
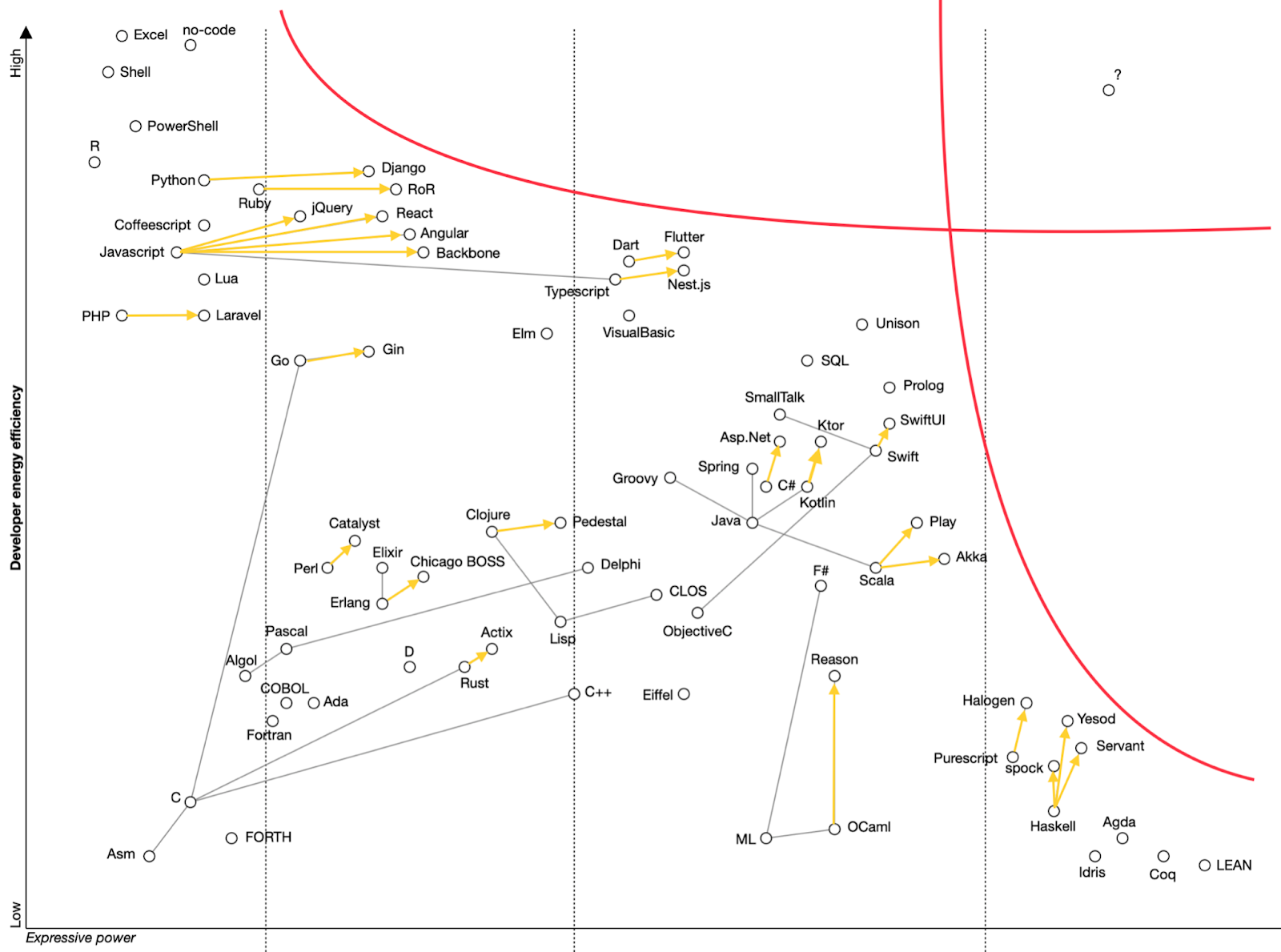
The red lines are limiting functions. The top one marks the limit of applicability of highly energy efficient (easy) tools to build complex solutions. Indeed, one can easily pick up and start building with very energy efficient tools like Excel or shell, but these tools can’t scale to build big, complicated applications. The more advanced and complicated solution is required, the more complicated (less energy-efficient from human brain point of view) tools are becoming.
The right red line marks cognitive load limit. The more powerful and thus complicated tools become, the more cognitive load they cause to the brain, become less energy efficient, up until they are out of reach for industrial applications.
Red lines and yellow arrows show us the direction of evolution of software development. We can see that it is kind of cornered between red lines, and some kind of phase shift will be required to transcend into the top right corner. We can also expect that some existing elements could quantum tunnel behind the lines, due to the probabilistic, quantum-like nature of system abstraction we work with. That will not create a statistically significant effect though.
One more thing to note is that the bottom right cluster is not useless, but is a source of ideas other clusters abduct from.
The Game
Now, why are there clusters still? Programming is managing complexity. According to Complexity theory, complexity can’t be controlled, but can be managed by setting boundaries, constraints, and then adding attractors which direct the system in the desired direction (or remove ones which lead to a wrong direction).
Let’s split the area into zones around clusters and see what methods of dealing with complexity are used in these zones:
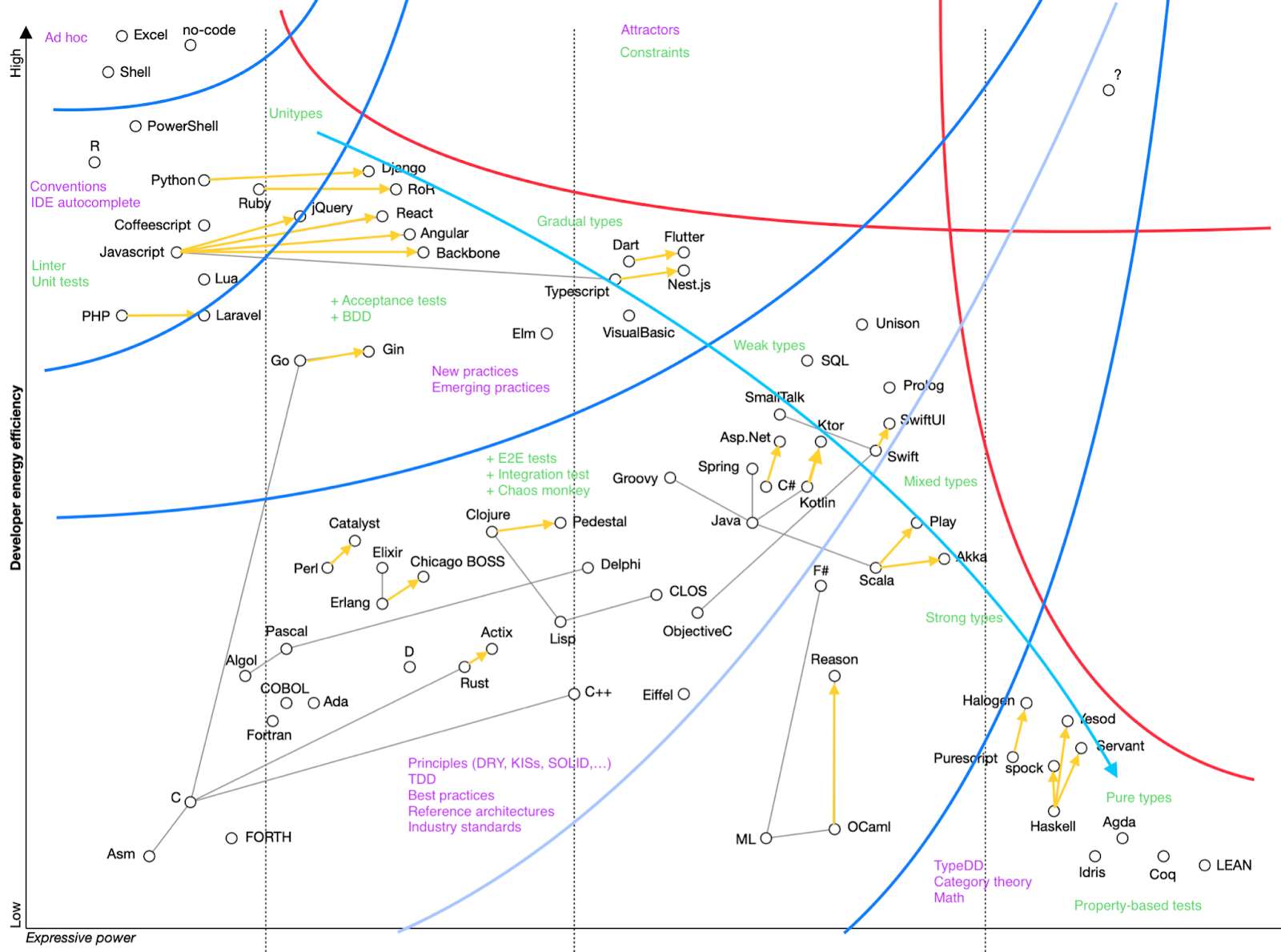
So here are the constraints and attractors1 used in different complexity zones. We can see nice spectrums of type systems, testing, practices, from very loose to very ordered ends. The boundaries2 between zones aren’t rigid either, rather the whole plane is a complexity spectrum. Nonetheless these boundaries are real, and crossing them is a phase shift, and takes energy.
1 IDE autocomplete is an attractor because it directs software development system to a more stable state, by improving energy efficiency of programmers, leaving less space for errors and more cognitive capacity to work on other issues.
Description of a problem to be solved is the ultimate attractor - it directs software development in the required direction.
Attractors do indeed direct the system to the desired state – in our case this is the energy-efficient development process, on all stages of its evolution from a chaotic starting state to a complicated maintenance or legacy state. Principles, conventions, autocomplete, reference solutions, examples etc are all attractors.
Some attractors can be enforced, they become constraints, like linter rules etc. Tests, type systems can be enforced and thus can be used to set up constraints.
Boundaries are the outermost constraints, like a chosen programming language, or a framework (in the sense of Akka, Erlang actors) - we choose to operate within this space, bound ourselves into it.Then we set enabling and governing constraints, like tests and type signatures, to limit ourselves inside the boundaries, and then we use whatever we have to guide us in the desired direction - principles, goals etc.
2 Think about a chemical substance, like water. It can be in solid, liquid, gas, plasma states. These states have different complexity properties. It takes energy to cross from one state to another. Such crossings are known as phase shifts. The substance absorbs or gives away energy, changes its complexity and entropy between states.
An outer system (you for example) has to spend energy either way on energy management and own operations while making phase shifts happen to the substance. The overall entropy of the word increases in any case.
The substance, water, is a software product we are building. The process of building it is the software development process we are analyzing here. To bring the product to the desired state we have to spend energy. This energy spending displays spikes when crossing complexity zones boundaries.
Think energy spend on maintaining the existing application, just fixing bugs and adding minor features, vs migrating the whole thing to a new architecture/framework/data model/microservices whatever.
This picture reminds of another framework for managing complexity, namely Cynefin:
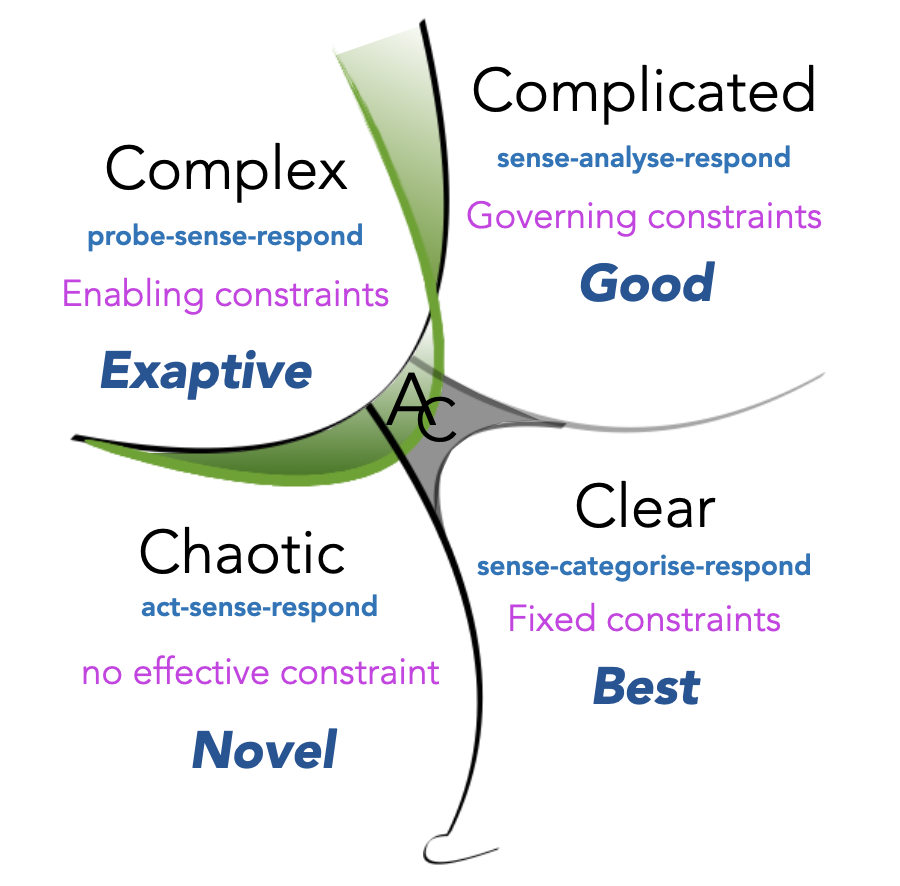
We can see, for example, how the area with no or ad hoc constraints changes into the area with enabling constraints (unit tests, IDE autocomplete, gradual types) changes into the area with governing constraints (E2E test, integration tests, strong type systems) change into the area with fixed constraints (pure, deterministic type systems, exhaustive property-based tests).
What we’ve discovered so far is that the software development tools spectrum is clustered into areas on the chart, and these areas demonstrate different approaches to managing complexity, which match with complexity domains of Cynefin. We even have liminal areas on our chart when some technologies are at the edge of different zones, and can exact or abduct useful properties from other zones, or switch to them for easy experimentation.
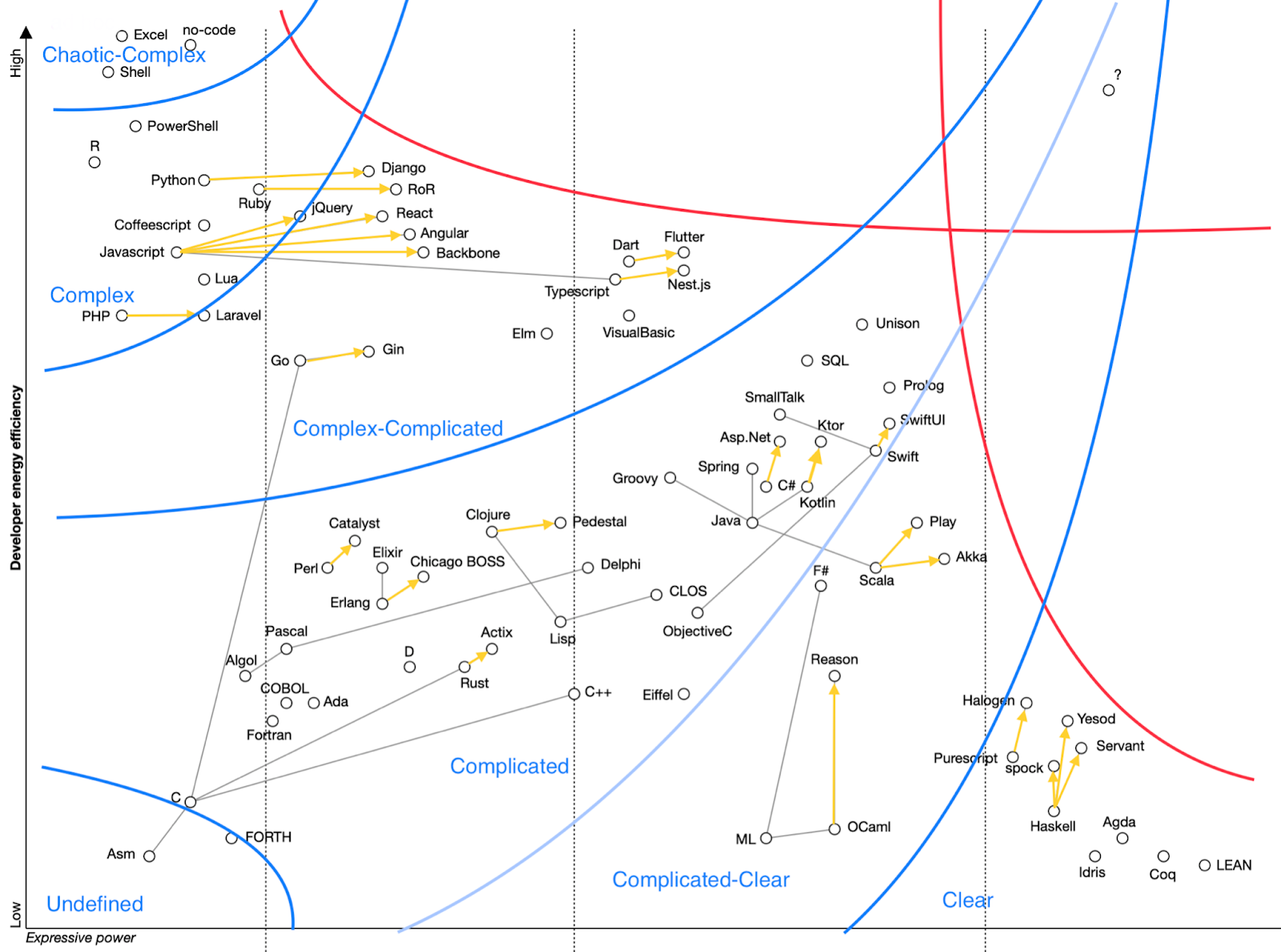
This is a rather remarkable result! Cynefin is an established framework for managing complexity, with its own methodologies and applications in other domains, and now we can use it to approach the technology part of software development too.
Software products are complex systems, and they evolve from genesis, chaotic state to complex to complicated and finally to an ordered legacy system. Different approaches and tools are needed at different stages, like the ones allowing to address change cost minimisation before reaching an MVP, then waste cost minimisation while scaling the product up, and regressions cost minimisation for established, legacy products.
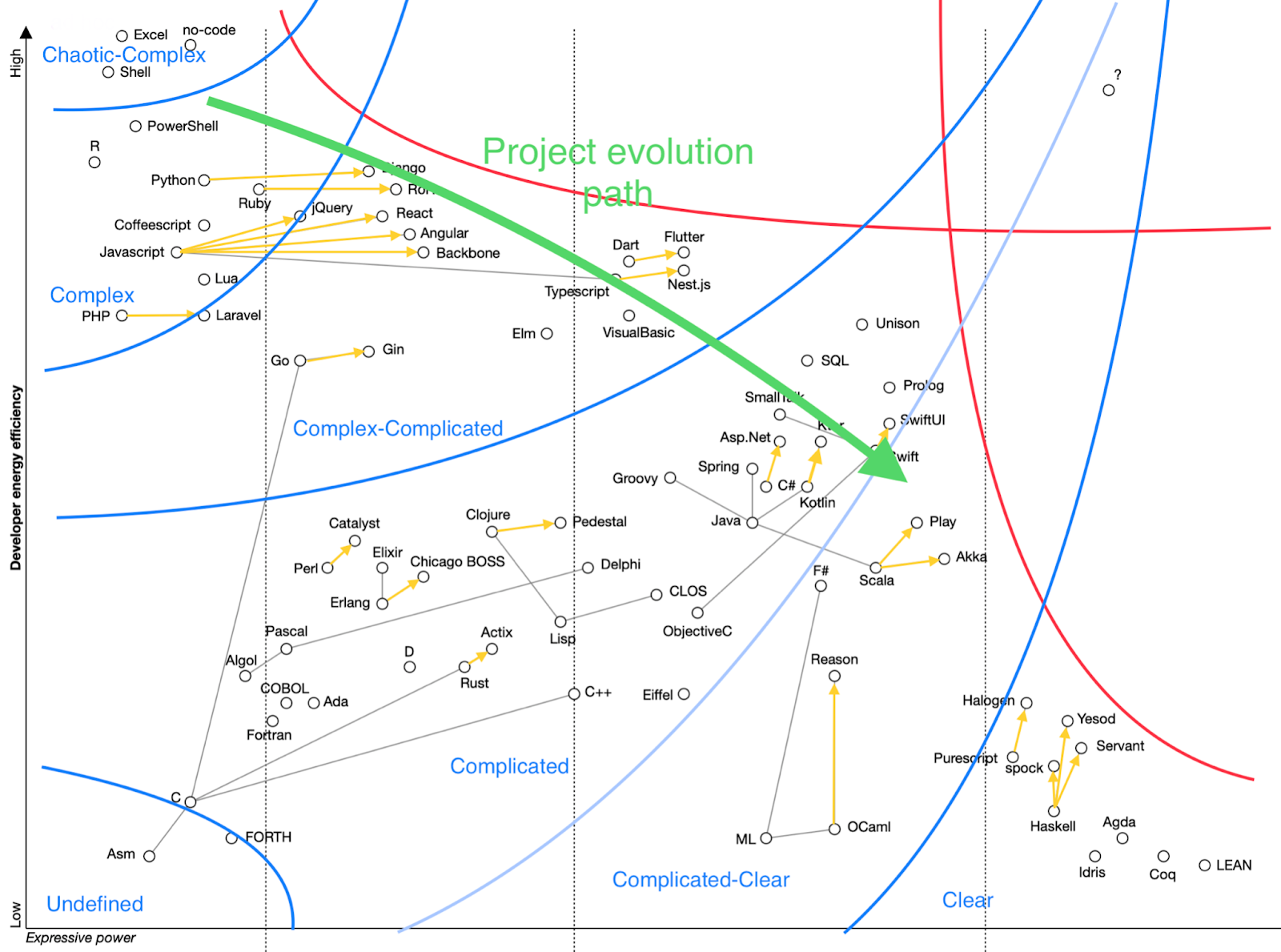
Note that software product development evolution is a different evolution than the software development technology evolution. This article mostly talks about the latter, unless specified otherwise. The former is an emergent entity of the software development process.
Software product development evolution follows the complexity evolution path. Complexity evolution drives selection of the right processes, teams, people, and tools for each stage.
The right tool for a job
Now we can see how different technologies provide the required properties for different stages of product evolution. This chart guides us through technology choices, provides insights on the ages-old question – what does it mean: the right tool for the job?
During product evolution we need different ways to address complexity management. At first we want quick success, no constraints tools for initial exploration and modelling. We can see that we don’t need to write tests in this zone. Then we need tools which provide us with enabling constraints for quick experimentation around established kernels. This means linters, conventions, unit tests. Then we need guiding constraints to help us scale the product fast and without breaking things. Most products want to stay in this zone. In rare cases we need to make the product have deterministic properties, be a completely ordered system – we have tools for that as well.
That said, changing programming languages and frameworks during product lifetime isn’t an easy task. So we want ways to address changing complexity nature of the product without remaking it from scratch every time. The chart can provide us with answers to this question as well!
First obvious answer is that we need a tech stack which allows adding and changing concrete constraints and attractors on the fly. There are some tools doing just that on the chart, e.g. Javascript->Typescript transition, or other examples of gradual types.
Less obvious answer is architecture. Good architecture moves every element it is applied to to the right, and to the top. Architecture is an evolution catalyst. On the other hand, bad architecture can easily move the element to the left or to the bottom. We can use this chart to evaluate and verify a proposed architecture.
It is worth mentioning that this framework can be applied not just to software development, but to any other domain of similar structure.
Worse is better
Another question answered is why worse is better. Energy efficiency is one of the main drivers of evolution, and we see that the most energy efficient tools are at the top of their specific zones.
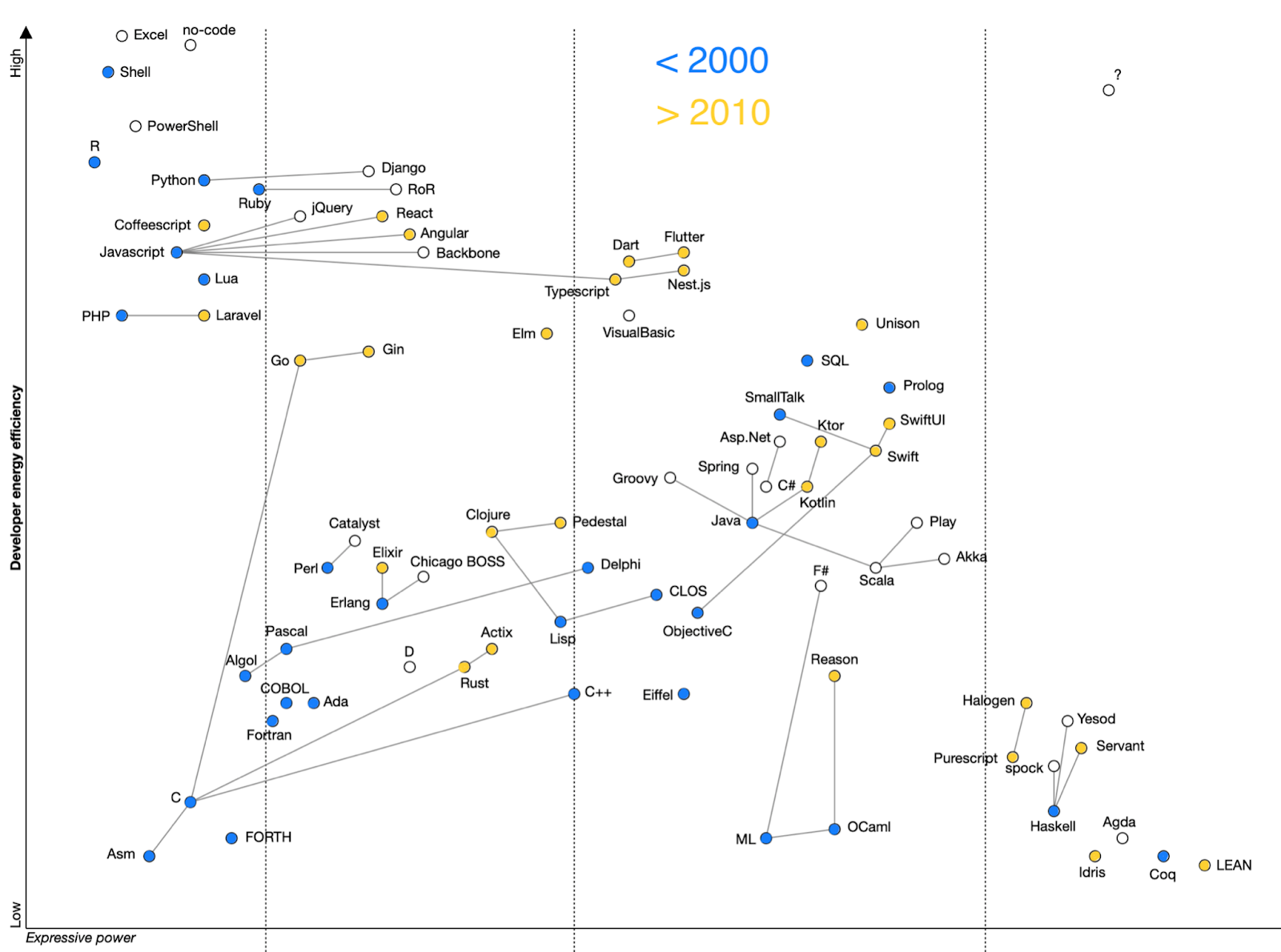
We can also see that complexity management approaches are more loose at the top too. This means less ordered elements win the evolution, and less ordered means worse from an absolutist point of view. Entropy ensures new elements are created at random places3, and then ones which do the job with highest energy efficiency win adoption.
3 Entropy is an emergent, higher-order property of systems, which manifests itself while confirming to all the laws which are in effect.
In our system here the laws are energy-efficiency pull and complexity growth pull. These forces shape the landscape. One way to define entropy in this system is as a measure of disorder within what is allowed by laws.
The fact that the yellow dots and the blue dots are distributed almost uniformly AND within existing clusters exactly corresponds to the expected outcome. This observation actually does hint at that entropy is in play.
Entropy, in turn, is essential for evolution, and we happen to observe evolution on a yet higher level. This also hints at the entropic nature of the system.
Deeper origins of entropy are informational, related to the amount of hidden information in quantum entangled states, as far as current understanding in physics goes.
Our system does exhibit some quantum properties, and I think the origins of its entropy could be traced back to this quantum entropy as well. But that would require a whole new article in itself.
Indeed, we can see that blue, yellow and white elements are distributed uniformly across the chart:
Beyond technology
Using Cynefin bridge we can transcend the technology map and connect it to project management methodologies required at different project stages. We can see that different processes, different team structures, even different psychological attitudes and neurophysiological types of thinking are required together with different technologies at different project stages.
At early stages projects are in the chaotic-complex domain, this means non-linear explorations and experiments. Technological tools and approaches here align well with non-linear, very quick iteration development process, pre-scrum, XP methods.
After finding product-market fit and reaching MVP products enter the scaling phase, which benefits from enabling constraints both in tech and in project management dimensions. That’s scrum, sequential short iterations.
Further down the product development line there exists already quite a lot of functionality, the product is complicated, has some internal order which has to be preserved and maintained. This is an area of governing constraints, again, both in tech and in project management. From the point of view of the latter it is something like Shape Up, or Scaled Agile as it was supposed to be - longer iterations, which include strategic design phases, coherent workflow. Legacy systems can be largely maintained this way too.
Mission-critical applications, which need to be implemented as ordered systems, require a lot of up-front design and architecture process, and rigorous correctness verification, are best addressed with a waterfall-like process, though each step can have its own pace and complexity, from chaotic explorations in design step to long-lasting support phases4.
We can connect to other frameworks, like explorers, settlers, town planners team attitudes – and now we can provide them with the right tools for their respective jobs.
Also, each person’s brain works differently. There are three types of thinking the brain works by, and usually one of them is dominant. Some people are good at ordering things – this method of thinking works best in ordered and complicated complexity domains, within respective processes and with appropriate tools.
Some are good at abstracting and finding the essence of things – this is a good match for complex and occasionally chaotic domains, where creativity, inventions and innovations happen.
Some are good at reflecting other people and building relations between elements – they are a good match for customer-facing roles. We can use this map to assess which task a person is best at, and vice versa, assign one a job they are most effective at.
4 There is an example when mission-critical applications were developed in a highly agile environment – NASA's Commercial Crew Program, where SpaceX won the competition.
This fact does confirm, actually, the evolutionary pull towards the top of the chart.
As I mentioned elsewhere in the article, people are indeed giving up attempts to build ordered systems using waterfall methods, and turn to more appropriate from the complexity theory point of view ones – build in the complicated domain using constraints and attractors and agile methods.
Chaos Monkey is a perfect example of using a negative attractor for the greater benefit.
The Future
Now let’s take our attention to the top right corner of the chart. There is nothing there. This is the place for the future of software development technologies. We can use the chart to predict which properties these future solutions must have.
It is logical to assume that future technologies will still need to address different complexity domains of product evolution. So we must expect a spectrum of tools, not a single silver bullet.
Next, we see that these tools need to cross the limiting functions boundaries – be more advanced than human cognitive capacity, and be more energy-efficient than current solutions. Energy efficiency means automation, and high cognitive load means domain expertise by machines. Crossing these lines is also a phase shift, so it would require a lot of energy to build such technologies. We can also assume that these solutions would consume lots of energy to operate, because making complex things have simple interface means reducing local entropy, and, since entropy never decreases, we must expect an increase of global entropy, that is energy consumption.
Crossing both energy efficiency and complexity limits also means programming becomes a commodity – everyone, not just programmers, can take such a tool, throw in a description of the task to solve, and get the resulting application back.
As mentioned earlier, complexity is managed by setting boundaries, constraints, and adding attractors. We can expect the future tools to be bounded (domain-specific), and able to infer automatic constraints, probably from the body of domain knowledge. Automatic constraints means domain- or task-specific tests and universal standard architectural elements. In more advanced applications we can expect local types be automatically inferred from domain body of knowledge and local logical context.
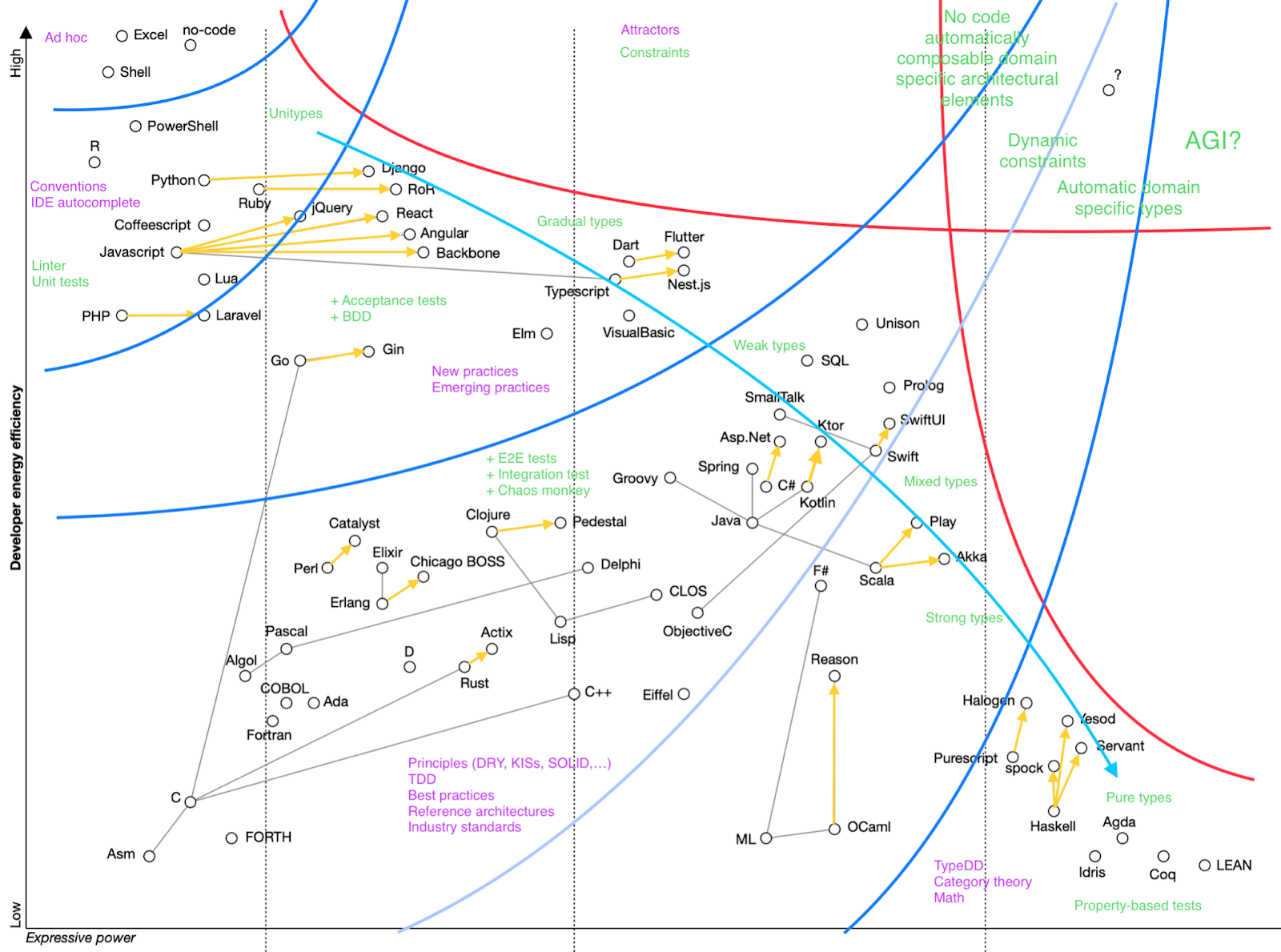
One example could be something like Amazon Lambda. It does a great job of improving energy efficiency and hiding much of essential complexity, but it does create its own complexity, and doesn’t address business tasks. It would need a library of universal architectural elements, and an automatic solution to combine them together around an attractor – a description of a problem that needs to be solved.
Another example would be Github Copilot, which has been announced right after the first draft of this article was published, literally on the same day. It is a rather bold approach to make an “AI” to write code on a function level based on a pattern, like function name or comments content. As far as I understand it currently works on a statement (words) level, without understanding any semantic objects from the code. But even in this way it looks impressive and promising. It addresses the energy efficiency limit by generating code snippets automatically, which is next to IDE autocomplete on the chart. Great start nonetheless!
In the most extreme cases and in the more distant future we probably should expect something like «domain specific weak AGI».
Eugene Naumenko
See other articles by Eugene

WorksHub
Jobs
Locations
Articles
Ground Floor, Verse Building, 18 Brunswick Place, London, N1 6DZ
108 E 16th Street, New York, NY 10003
Subscribe to our newsletter
Join over 111,000 others and get access to exclusive content, job opportunities and more!